

u8,u8国际,u8国际官方网站,u8国际网站,u8国际网址,u8国际链接,u8体育,u8体育官网,u8体育网址,u8注册,u8体育网址,u8官方网站,u8体育APP,u8体育登录,u8体育入口Skill 是一个文件夹,里面装着指令文档、参考资料、可执行脚本等资源。AI 拿到它,就能胜任一项原本不会的特定工作。
比如一个pdf-editor技能文件夹里,可能有一份怎么处理 PDF的操作指令、一个旋转 PDF 的 Python 脚本、一份 API 参考文档——AI 不需要从外部再找任何东西,这个文件夹里全有了。
这个概念不限于某一个产品。无论是 Codex、Claude 还是其他 AI Agent,skill 的本质都一样。你可以把它理解为 AI 的一个能力插件——插上去,AI 就多了一项专长;拔掉,AI 还是原来那个通用助手。
SKILL.md的结构很简单——上半部分告诉 AI什么时候用我,下半部分告诉 AI具体怎么做:

上半部分叫frontmatter(---之间的 YAML),包含name和deion两个字段。AI 在每次对话开始时都会扫描所有已安装技能的 frontmatter,靠 deion 来判断这个技能和当前请求相关吗——这是技能的唯一触发点。
下半部分叫body(Markdown 正文),是技能被激活之后才加载的操作指令。如果技能没被触发,AI 永远不会读到这里。
比如你要做一个PDF 处理技能:SKILL.md 里写了处理流程,但旋转 PDF 的代码每次都一样,每次让 AI 重写既浪费时间又可能出错——不如直接放一个写好的 Python 脚本。再比如前端项目生成器技能:每次都要一套 HTML/React 的样板文件,不如直接放一个模板目录让 AI 拷贝出来改。
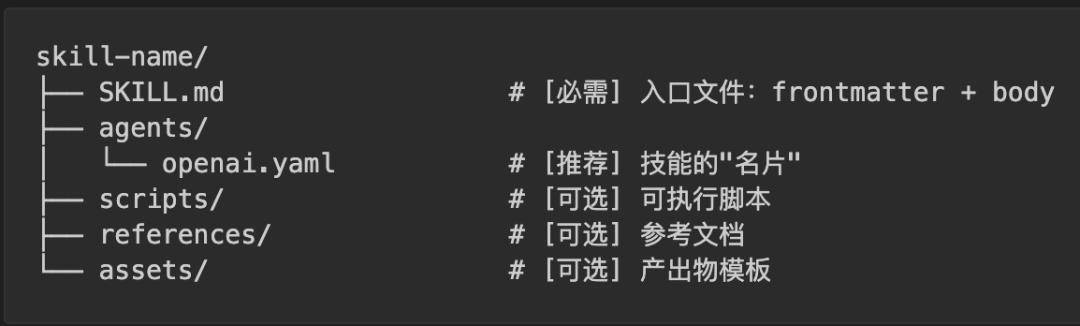
references/— AI 在工作过程中需要查阅的参考资料。比如一个BigQuery 查询技能,AI 要知道公司有哪些表、每个表有什么字段,这些信息放在references/schema.md里,AI 需要时再读取。和 s 的区别是:references 是给 AI读的,s 是给 AI执行的
assets/— 不是给 AI 看的,而是直接用在最终产出里的文件。比如一个前端项目生成器技能,assets/frontend-template/里放着一套 HTML/React 样板代码,AI 直接把这套模板拷贝出来,在上面修改。再比如assets/logo.png是公司 logo,AI 生成网页时直接引用它。AI 不需要读懂一张 logo 图片,只需要知道它在哪、什么时候放进去
agents/openai.yaml— 技能的名片。很多 AI 产品会在界面上展示一个技能列表,让用户选择或搜索。这个文件里存的就是列表中显示的名称、简介、图标等信息。它不影响 AI 的行为,纯粹是给产品界面用的
references/— AI 在工作过程中需要查阅的参考资料。比如一个BigQuery 查询技能,AI 要知道公司有哪些表、每个表有什么字段,这些信息放在references/schema.md里,AI 需要时再读取。和 s 的区别是:references 是给 AI读的,s 是给 AI执行的
assets/— 不是给 AI 看的,而是直接用在最终产出里的文件。比如一个前端项目生成器技能,assets/frontend-template/里放着一套 HTML/React 样板代码,AI 直接把这套模板拷贝出来,在上面修改。再比如assets/logo.png是公司 logo,AI 生成网页时直接引用它。AI 不需要读懂一张 logo 图片,只需要知道它在哪、什么时候放进去
agents/openai.yaml— 技能的名片。很多 AI 产品会在界面上展示一个技能列表,让用户选择或搜索。这个文件里存的就是列表中显示的名称、简介、图标等信息。它不影响 AI 的行为,纯粹是给产品界面用的
知道了 skill 是什么,下一步就是写一个。但大多数人第一次写出来的 skill 都有同一个问题。
## 背景本技能基于团队多年的代码审查经验总结而成,旨在提升代码质量和团队协作效率。
## 审查原则-保持专业、建设性的语气-关注代码质量而非个人风格-平衡严格性和灵活性
## 使用方式当用户提交代码时,对代码进行全面审查,给出改进建议。注意保持友好和鼓励的态度。
如果这是一份给人看的团队文档,它写得不错——有背景、有原则、有使用方式,甚至还有版本记录。
基于团队多年经验总结— AI 不关心这个技能是怎么来的,它只需要知道现在该怎么做
保持专业、建设性的语气— 人类读了能 get 到一个大致的感觉,但 AI 会把专业和建设性展开成无数种组合,每次输出都不一样
平衡严格性和灵活性— 人类经验丰富的审查者知道什么时候严格什么时候灵活,但 AI 没有这个直觉,这句话等于没说
全面审查,给出改进建议— 这是对人类审查者的期望,但 AI 需要的是:先检查什么?再检查什么?什么问题必须指出?什么问题可以忽略?
版本记录— AI 每次被唤醒都是全新的,v1.0 还是 v1.1 对它没有意义
deion 只写了代码审查技能— AI 靠 deion 判断是否触发,代码审查技能五个字太模糊:用户说帮我看看这段代码要触发吗?这个函数性能怎么样要触发吗?
基于团队多年经验总结— AI 不关心这个技能是怎么来的,它只需要知道现在该怎么做
保持专业、建设性的语气— 人类读了能 get 到一个大致的感觉,但 AI 会把专业和建设性展开成无数种组合,每次输出都不一样
平衡严格性和灵活性— 人类经验丰富的审查者知道什么时候严格什么时候灵活,但 AI 没有这个直觉,这句话等于没说
全面审查,给出改进建议— 这是对人类审查者的期望,但 AI 需要的是:先检查什么?再检查什么?什么问题必须指出?什么问题可以忽略?
版本记录— AI 每次被唤醒都是全新的,v1.0 还是 v1.1 对它没有意义
deion 只写了代码审查技能— AI 靠 deion 判断是否触发,代码审查技能五个字太模糊:用户说帮我看看这段代码要触发吗?这个函数性能怎么样要触发吗?
每一条单独看都没啥问题,但它们都是写给人看的。问题不在于写得不够多,而在于写错了对象。
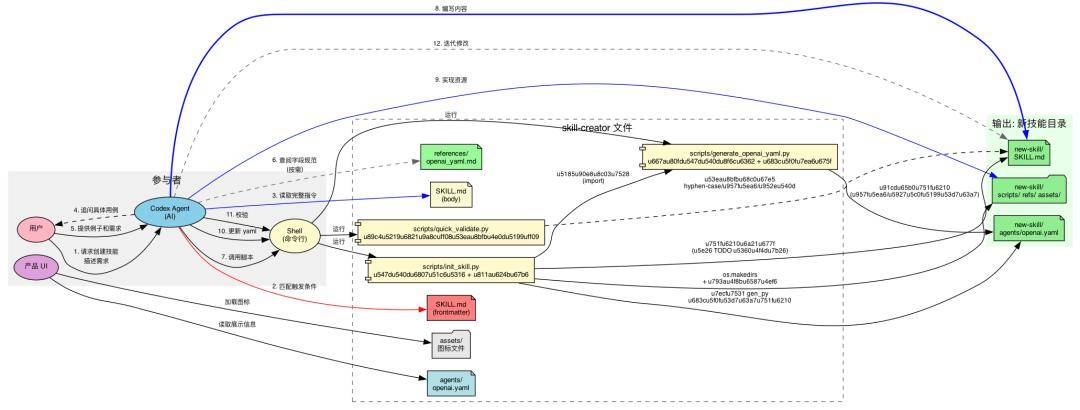
那正确的写法是什么样的?我们来看一个现成的答案——codex的skill-creator。它是一个创建 skill 的 skill,它自己的 SKILL.md 就是一份关于如何给 AI 写指令的最佳实践。
打开 skill-creator 的 SKILL.md(约 370 行),在深入任何细节之前,我们先建立对它的整体认知。
skill-creator 要解决的问题只有一个:怎么在有限的上下文窗口里,给 AI 最有效的指令?
AI 的上下文窗口是有限的,而且是共享的(系统提示、对话历史、所有已安装技能的元数据都在里面)。你的 skill 占得越多,留给其他用途的就越少。所以 skill-creator 的第一原则就是:每一句话都要值得它占用的 token。
不是所有信息都需要一开始就加载。skill-creator 设计了一个三级分层架构,让不同的信息在不同的时机进入上下文:
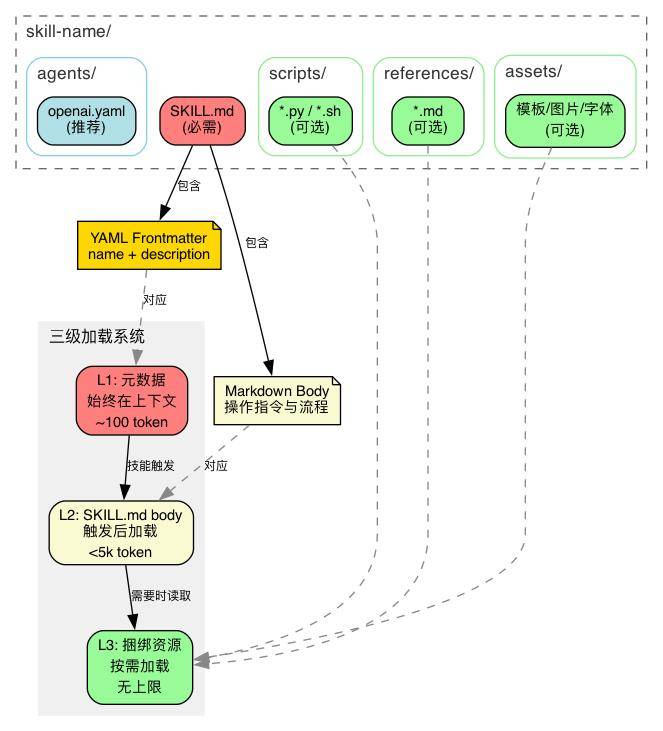
L1(元数据):始终在上下文中,约 100 词——AI 靠它判断要不要激活这个技能
L2(SKILL.md body):触发后才加载,控制在 5k 词以内——操作指令
举个例子:让AI 写一篇技术博客,十个人写出十种风格都可以——你只需要给方向,具体怎么写让 AI 自己决定。这就是高自由度。
但让 AI 生成一个 YAML 配置文件就不一样了。比如 skill-creator 要生成的openai.yaml,里面有个short_deion字段,要求 25-64 个字符、首字母大写、不能有引号。AI 写成 65 个字符?不行,产品界面会截断。写成 24 个字符?不行,校验不通过。漏了首字母大写?界面显示不一致。这种任务差一个字符就出问题,你不能让 AI 自由发挥,必须用脚本来锁死格式——这就是低自由度。这类任务叫脆弱操作:不是说它复杂,而是说它做对只有一种方式,做错有一百种方式。
有了原则和架构,skill-creator 最后给出了一个六步创建流程,把设计思想变成可执行的操作步骤:
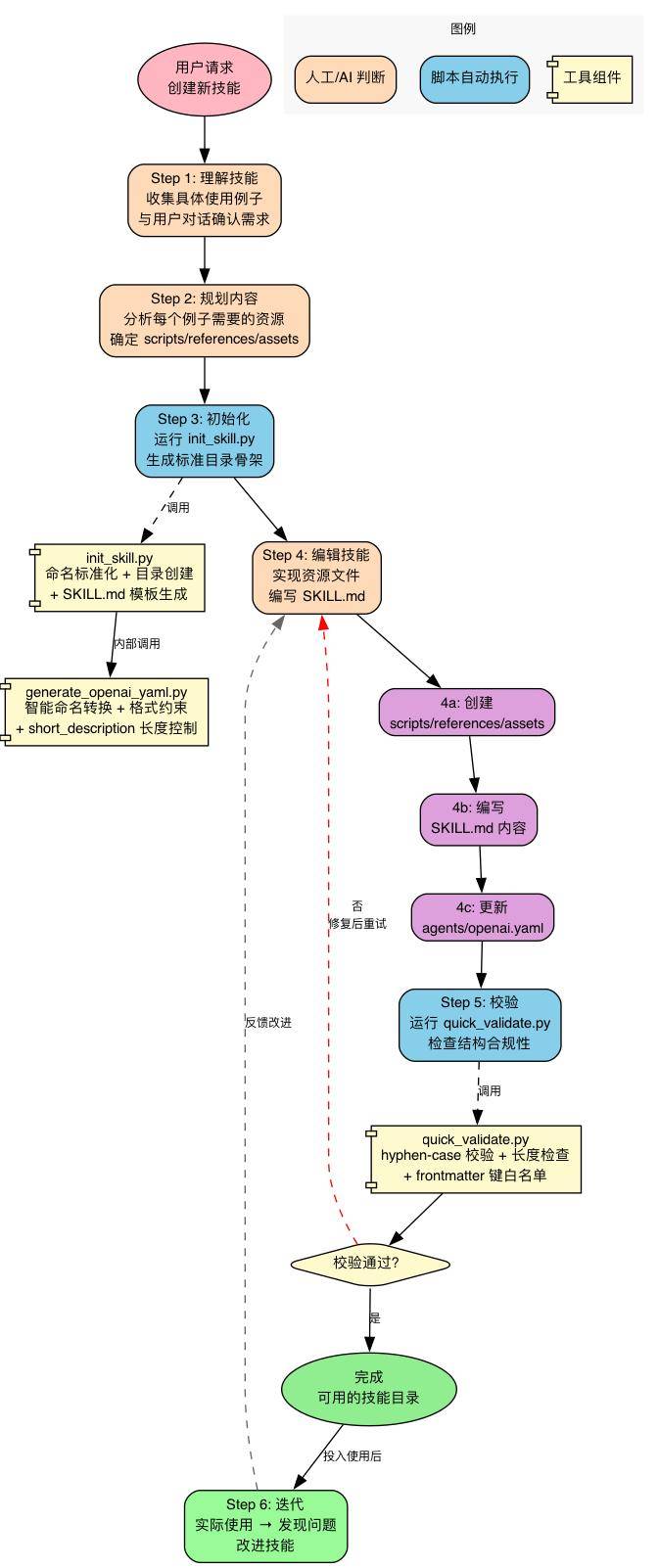
理解→规划→初始化→编辑→校验→迭代。其中脚本代码贯穿流程,形成确定性的保障:
AI 的上下文窗口就像一张工作台——它同一时间能摊开的资料是有限的。而这张工作台上已经放着不少东西了:系统自己的规则、用户之前说过的话、所有已安装技能的简介。你的 skill 一旦被激活,它的内容也要摊上去。工作台就这么大,你占得越多,留给其他东西的空间就越少。
既然工作台空间有限,那写 skill 时怎么判断一段内容该不该放进去?skill-creator 给了一个前提假设:AI 本身已经很聪明了,你只需要补充它不知道的东西。
AI 是不是已经知道这个了? — 比如Python 的 for 循环怎么写,AI 当然知道,不用教
这段内容值不值得占用工作台上的空间? — 一段 200 字的解释,能不能用一个 10 行的代码示例替代?
AI 是不是已经知道这个了? — 比如Python 的 for 循环怎么写,AI 当然知道,不用教
这段内容值不值得占用工作台上的空间? — 一段 200 字的解释,能不能用一个 10 行的代码示例替代?
实操推论:用简洁的示例代替冗长的解释。一个好的代码示例胜过三段文字描述。
原因很简单:skill 的读者是 AI,不是人类开发者。AI 不需要安装指南、更新日志、快速参考这些人类辅助文档。每一个多余的文件都是噪音。
这种正面描述看起来清晰,但对 AI 来说,温暖的程度、克制和有洞察力之间的平衡——全是模糊空间。
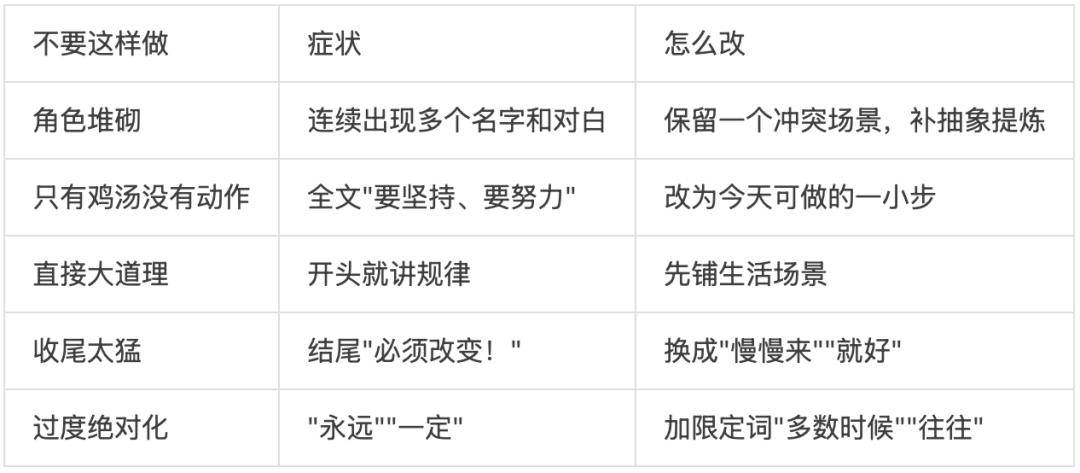
当你写完 SKILL.md,做一次反转测试:每一条正面指导,能不能改写成不要做X的形式?如果可以,改写后通常更精确。
在第三章的框架总览中,我们已经看到了三级分层架构的全貌。这一章展开讲它的细节。
L1 是过滤器— 从几十个已安装技能中筛选出当前需要的那一个。deion 不精确 → 误触发或漏触发
L2 是操作手册— 触发后告诉 AI 该怎么做。太长 → 注意力被稀释。body 控制在 500 行以内
L3 是工具箱— 只在需要时打开。其中 s/ 最高效——执行而不读入,零 token 成本
L1 是过滤器— 从几十个已安装技能中筛选出当前需要的那一个。deion 不精确 → 误触发或漏触发
L2 是操作手册— 触发后告诉 AI 该怎么做。太长 → 注意力被稀释。body 控制在 500 行以内
L3 是工具箱— 只在需要时打开。其中 s/ 最高效——执行而不读入,零 token 成本
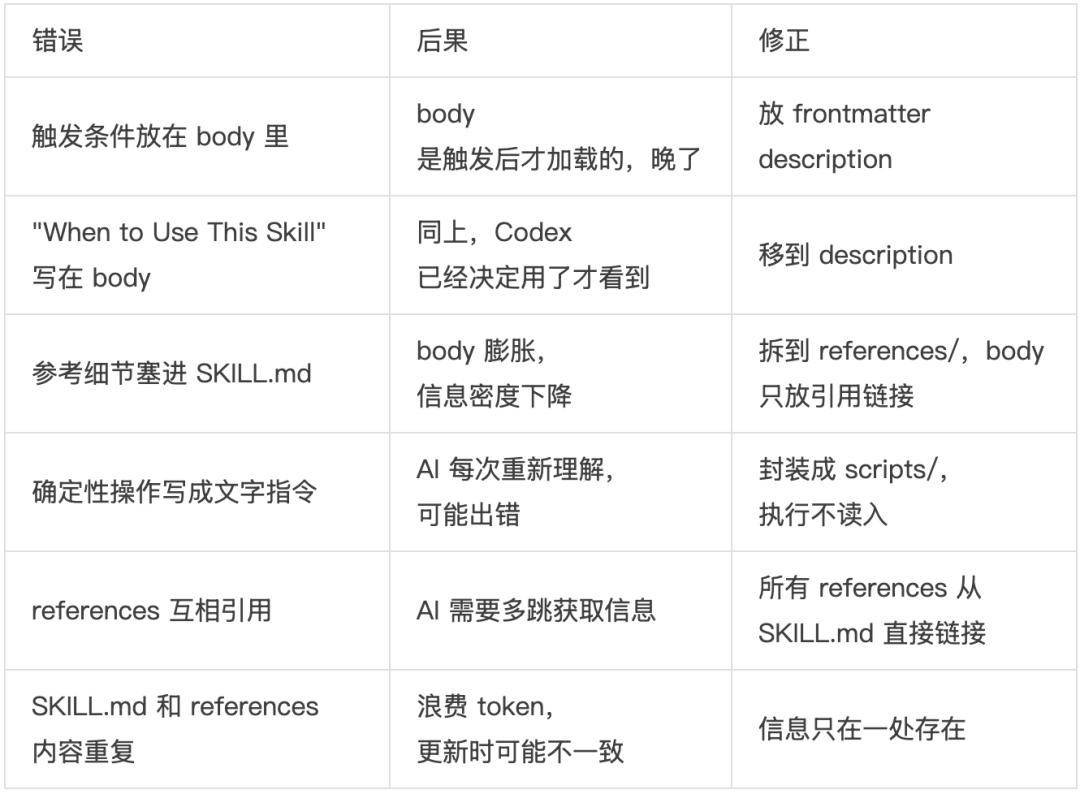
把所有when to use信息放在 deion 里,不要放在 body 里。body 是触发后才加载的,那时候 Codex 已经决定用了,什么时候用的信息已经迟了
把所有when to use信息放在 deion 里,不要放在 body 里。body 是触发后才加载的,那时候 Codex 已经决定用了,什么时候用的信息已经迟了

可执行代码(Python/Bash 等),用于需要确定性可靠性或反复重写的任务。
用途:数据库 schema、API 文档、领域知识、公司政策、详细工作流指南
核心优势:保持 SKILL.md 精炼,只在 Codex 判断需要时才加载
避免重复:信息应该只存在于 SKILL.md或references 文件中,不能两边都有。详细信息优先放 references,SKILL.md 只保留核心流程指令和工作流指导
用途:数据库 schema、API 文档、领域知识、公司政策、详细工作流指南
核心优势:保持 SKILL.md 精炼,只在 Codex 判断需要时才加载
避免重复:信息应该只存在于 SKILL.md或references 文件中,不能两边都有。详细信息优先放 references,SKILL.md 只保留核心流程指令和工作流指导
不是用来加载到上下文中的文件,而是直接用在 Codex 产出物中的资源。
核心优势:将输出资源与文档分离,Codex 可以使用它们而无需读入上下文
核心优势:将输出资源与文档分离,Codex 可以使用它们而无需读入上下文
知道了信息该放在哪里、该怎么约束,下一个问题是:AI 做什么,脚本做什么?
AI 非常擅长理解语义、生成文本、做创造性工作。但它不擅长精确格式控制、长度约束、命名规范——这些脆弱操作。
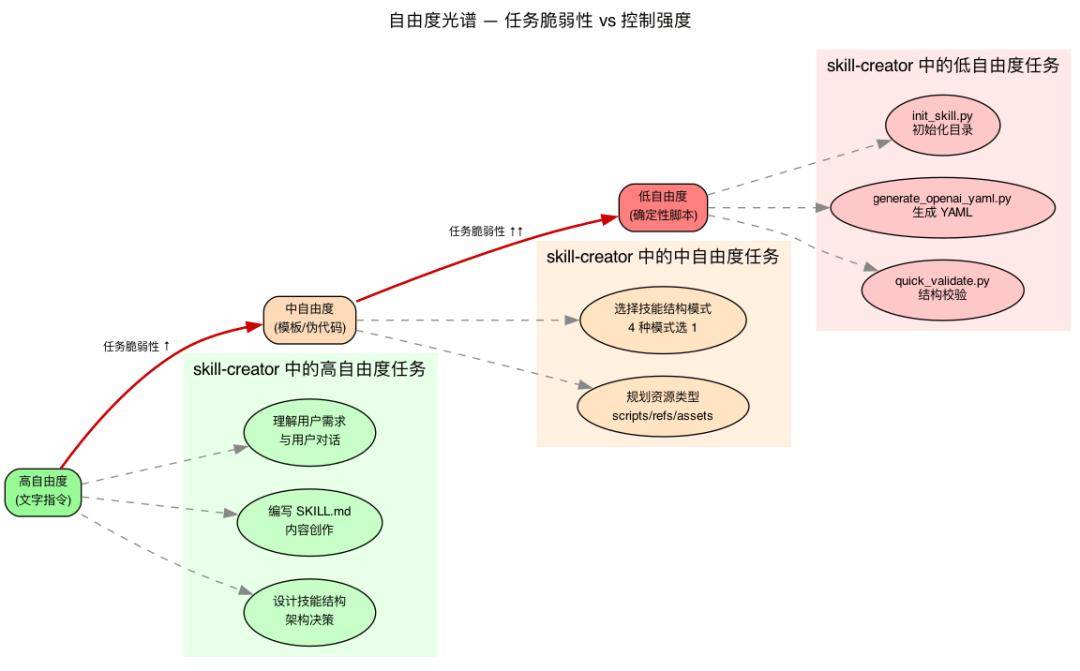
Skill-creator 用一个自由度光谱来处理这种不均匀性(见第三章框架图):
低自由度(具体脚本,少量参数):操作脆弱容易出错,一致性至关重要,必须遵循特定序列。
# 后果:short_deion 可能超过 64 字符限制,大小写可能不一致
Skill-creator 的做法:给结构比例(场景层 ≤30%,原理层 30-40%),但不锁定具体用词。
理解了自由度光谱,就能理解 skill-creator 为什么有三个脚本——它们就是低自由度的具体实现(脚本间的交互关系见第三章框架图)。
脚本是执行而不读入的——零 token 成本。你可以把任意复杂的确定性逻辑封装进脚本,而不用担心它占用上下文。这就是为什么 skill-creator 把命名转换(缩写词典、品牌词典)、长度约束(25-64 字符)、格式校验这些细碎但脆弱的操作全部交给了脚本代码。
需要理解上下文 → 文字指令有多种合理做法 → 文字指令需要创造性判断 → 文字指令
脚本的定义是执行,虽然有时仍需要被 Codex 读取(用于修补或环境适配),但大多数时候它们是执行而不读入的。
有了前面的原则和架构,skill-creator 最后给出了一个六步创建流程,把设计思想变成可执行的操作步骤(见第三章框架图)。
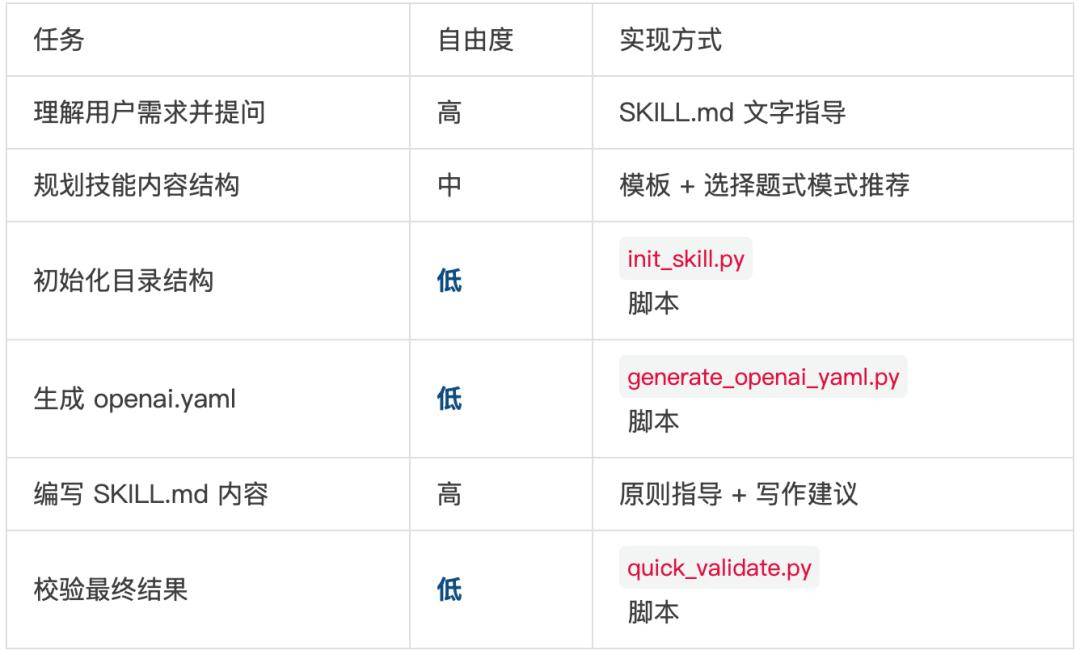
要创建一个有效的 skill,必须先清楚理解具体的使用例子。这些理解可以来自用户提供的例子,也可以来自生成的、经用户验证的例子。
image-editor 技能应该支持什么功能?编辑、旋转,还有其他吗?
image-editor 技能应该支持什么功能?编辑、旋转,还有其他吗?
完成标志:列出了所有要包含的可复用资源清单(s、references、assets)。
agents/openai.yaml的格式约束(字段长度、引号规则)靠手写容易出错
agents/openai.yaml的格式约束(字段长度、引号规则)靠手写容易出错
这一步可能需要用户输入(比如brand-guidelines技能需要用户提供品牌素材)
如果用了--examples,删除不需要的占位符文件。只创建真正需要的资源目录
这一步可能需要用户输入(比如brand-guidelines技能需要用户提供品牌素材)
如果用了--examples,删除不需要的占位符文件。只创建真正需要的资源目录
写给另一个 Codex 实例的操作指令。包含对 Codex 有帮助但不显而易见的信息:程序性知识、领域细节、可复用资源的使用方式。
校验 YAML frontmatter 格式、必需字段、命名规则。不通过就修复后重新运行。
首先明确Skill 是给 AI 写指令,而不是给人,Skill 本质是:用最少的 token,在正确的层级,给 AI 最精准的约束,让它在边界内自由发挥。